
在2017年著名的《Attention Is All You Need》发表后,以Transformer为基础架构的各种模型席卷了NLP、视觉甚至推荐领域,而这些年间对于Transformer的各种魔改也是层出不穷。那么它们的效果分别如何呢?在2021年, 论文《Do Transformer Modifications Transfer Across Implementations and Applications?》探讨了几种常见的Transformer“改进”(为何加引号看后续结果便知),并对其进行了实验比较,探讨之后Transformer的可信 的改良方式。在这比较中,所有的策略被要求是同等参数量或同等的操作数,因此可以认为是在同等资源性能下,各种方式的比较。话不多说,总结如下:
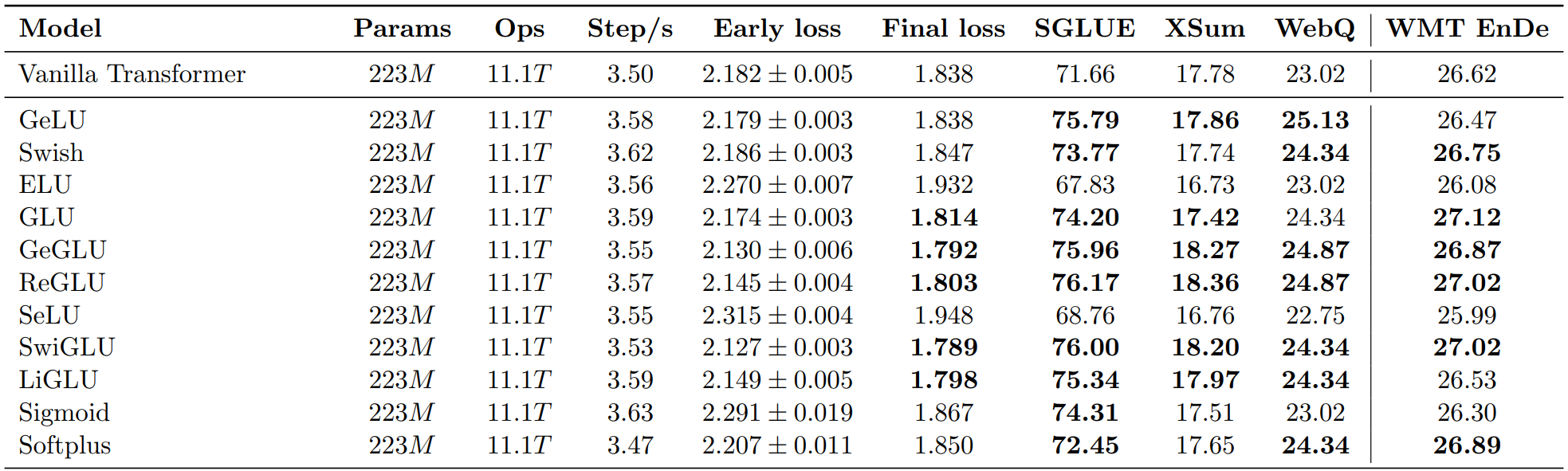
1.激活
探讨了常见的ReLUvs其他常见的激活方式,比如GeLU、Swish、ReGLU等
结论:GeGLU、ReGLU、SwiGLU相对原本的ReLU,提升会更大
2.归一化
19年论文《Root Mean Square Layer Normalization》中,探讨了去除掉Layout Norm中偏置项后(RMS Norm),Transformer效果会更好。此论文对此进行验证,并加入更多的方式比如Rezero等进行比较
结论:RMS Norm确实可以提升Transformer的效果,而其余Rezero等并不会对原本的Transformer做出改进。在Google的T5中,Transformer使用的也是RMS Norm而非Layout Norm。可以预见,未来RMS Norm将成为Transformer的标配。

3.深度
结论:在相同参数量下,越深的模型效果倾向越好,但由于深度增加,模型推理也变得越慢

4.BlockSharing
结论:无论是Encoder only、Decoder only还是全部,Block Sharing都不会提升模型效果,反而有所损害

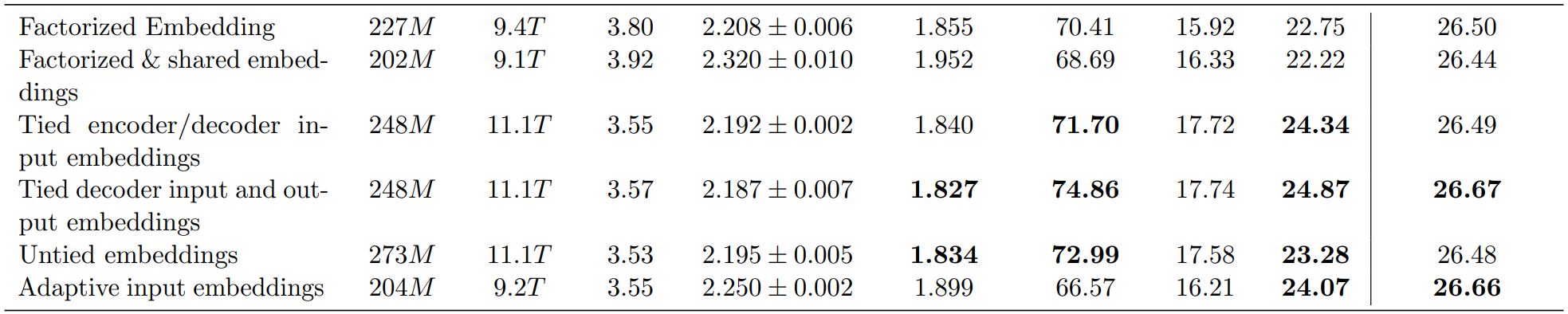
5.Embedding
结论:对于Tie/Untie Embedding以及其他各种操作方式。仅Untie Embedding可以略微提升效率,但此处也存疑,因为Untie Embedding后,相应参数量是增加的,可认为以下这些方式效果提升不大
6.SoftMax
结论:Mixture of softmaxes可以对效果有所提升,但这是在增加参数量、推理速度慢约40%的代价下达成的

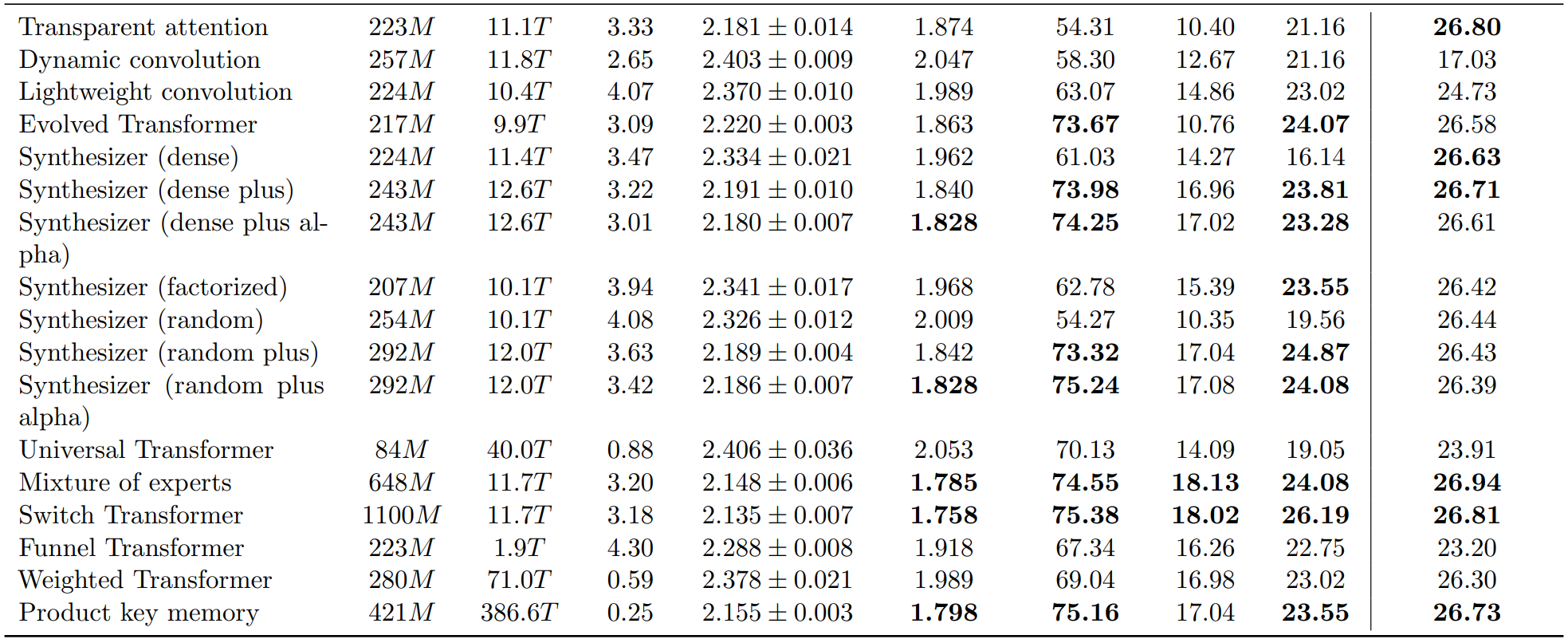
7.其他方式、综合性改动
结论:Switch Transformer、Mixture of experts、Product key memory可以有一定提升,而其他改动基本不会有有效提升。 此外,对于这三种改变,采用的方式基本类似于“使用大参数量/训练操作数,但在每次冻结一部分参数”的方式来做,模型中的Transformer结构与普通Transformer也并无区别
综合结论
令人惊讶的是,绝大多数论文对Transformer的“改进”都并不能称之为改进,很多论文都是水一水,炼了一波丹凑巧比原模型好就发出来了,实际基本无效甚至是负向作用。而如果想要有效地提升Transformer效果,更换使用GeGLU、ReGLU、SwiGLU等激活方式、使用RMS Norm归一化这两种方式都可以做到。 如果对资源性能要求不大,推理速度要求不高的情况,可以选择加深模型深度、使用Mixture of softmaxes、Switch Transformer、Mixture of experts、Product key memory这几种方式来提升性能。而对于其他方式,效果提升影响存疑,谨慎使用。