
本文为《如何生成文本: 通过 Transformers 用不同的解码方法生成文本》的概述
对GPT这种decoder only架构的模型来说,其在训练、预测中主要进行的是通过($x_0$,$x_1$,…$x_{n-1}$)个字符,来预测第$x_n$个字符应该是什么。在训练中,一般就是将真实的$x_n$作为ground truth与模型预测的结果进行交叉熵来进行训练。而在预测中,在获得($x_0$,$x_1$,…$x_{n-1}$)后,我们得到的是词表中所有 字符每个作为$x_n$的概率。为了生成一句完整的话,我们需要针对这些概率来实现一个选择策略,这就是生成模型的解码策略
贪心搜索
贪心搜索就是最简单的解码策略,它在每一步解码时,都选择概率最高的词作为当前输出词,如下图所示
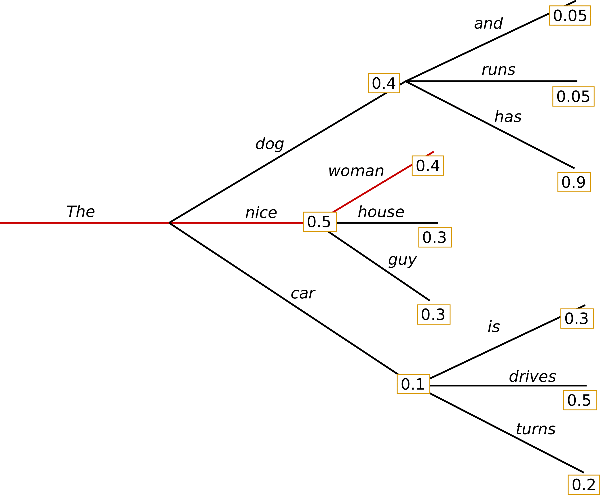
对于这个概率树,贪心搜索在第一步选择概率最高的“nice”,随后是“women”,因此最后的生成结果为“The nice women”‘
贪心搜索最大的问题即是贪心算法的普遍问题:贪心可以收敛到一个较优解,但某些场景则很难收敛到全局最优解。显然生成模型解码贪心不保证收敛到全局最优,比如这个例子中全局最优解为“The dog has”(概率为0.4 * 0.9 = 0.36),而非贪心结果“The nice women”(概率为0.5 * 0.4 = 0.2)
此外,生成模型在生成时还会碰到一个棘手的问题,那就是重复生成,比如模型会生成完全重复的句子不断重复下去“I enjoy walking with my cute dog, but I’m not sure if I’ll ever be able to walk with my dog. I’m not sure if I’ll ever be able to walk with my dog……”,或者生成 “排比句”无限下去“It’s hard to tell because it’s hard to describe. It’s hard to describe because it’s hard to think/ It’s hard to think because it’s hard to see……”,而贪心搜索无法解决这个问题
huggingface的transformers使用贪心搜索:不增加任何参数即是贪心解码
|
|
Beam Search
为了缓解贪心搜索的问题,Beam Search在每个步骤中不只选概率最大的,而是保留总概率最可能的num_beams条路径,以下图为例
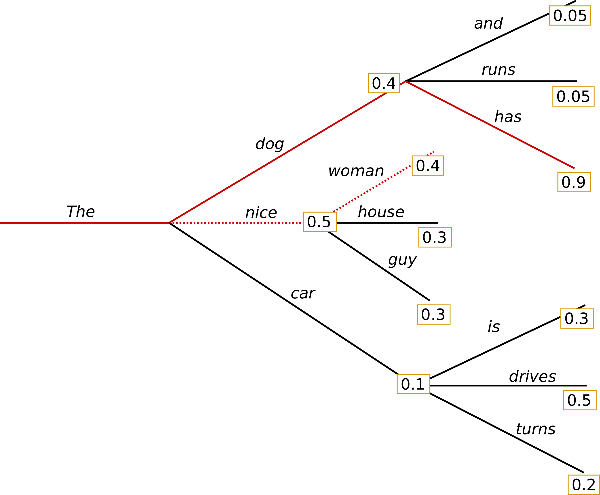
当num_beams=2时,第一次搜索将保留“nice”和“dog”两个词。随后在第二次搜索时,对“dog”和“nice”后面的每个词“and”、“runs”、“has”、“women”、“house”、“guy”得到本身概率乘以之前总概率得到所有可能路径的总概率,随后保留2条最大概率的路径“The dog has”和“The nice women”, 再继续检查“has”和“women”之后所有词,计算所有路径的总概率,保留num_beams=2条最大总概率路径,不断搜索下去。直到所有的beam生成EOS,结束生成,挑出总概率最大的一条路径进行输出
Beam Search在时间复杂度为贪心搜索的常数倍下,绝大多数情况都可找到比贪心搜索更优的序列。然而其还是不保证一定找到全局最优,且随着num_beams变小、生成序列变长,这种保证效力会逐渐减弱
此外,由于Beam Search只是“看得更广”的贪心,因此其同样无法规避重复生成的问题
huggingface使用Beam Search:加入num_beams参数并让early_stopping=True。此外,由于Beam Search在搜索时搜索了多条路径,因此返回时可以不止返回一条,而是返回num_return_sequences <= num_beams条文本
|
|
重复生成一个粗暴的解法是让某些长度为n的连续段落不出现两次,这个方法被称为n-grams惩罚,在huggingface的generate中,传入参数no_repeat_ngram_size=3,这样任意3-grams就不会出现两次。虽然它简单有效,但过于粗暴还是会影响模型的生成,当n-grams设置的n比较大时,其对于“排比句”式重复的去重能力大大下降,
且对于一些较短的重复无能为力(如no_repeat_ngram_size=5时模型只会将“它好烫烫烫烫烫烫烫烫”去重为“它好烫烫烫烫”)。但当n设置的过小,则某些高频词语和长文本生成又会受到大大损害。因此需要根据使用场景谨慎选择no_repeat_ngram_size
采样
相对于永远挑选最大概率的search方法,采样则并称随机性的概念,力求每次生成的结果都不同。这种观点有一些研究支撑,比如显示对话中,人类文本并不是挑选最大概率而说
因此,采样就是直接使用random,根据当前生成节点$x_n$个字符的概率,随机选择一个字符。然而,这种过度的随机很难保证生成通顺的文本,因此在采样时,一般会让高概率字符的概率更大,让低概率字符的概率更小。这一般是通过对输出字符概率的softmax操作时让原本的logits除以一个系数$\tau$来进行, 这个$\tau$被称为“温度系数”:
$$p_k = \frac{e^{x_k / (\tau+\epsilon)}}{\sum_k e^{x_k / (\tau+\epsilon)}}$$
可以看到相比于正常使用$x_k$的softmax,所有$x_k$都除以了温度系数$\tau$加一个防止除0的极小值$\epsilon$,一般来说使用时$\tau$取[0,1],这样经过e指数再归一后,各个字符的概率分布就更陡峭了。在$\tau=0$的极限情况下,温度缩放会退化为贪心解码,而在$\tau > 1$甚至取一个非常大的值时,温度缩放会退化为均匀采样
由于引入了随机,所以“采样”可以很好的对抗生成模型的重复生成问题
TopK采样和TopP(核)采样
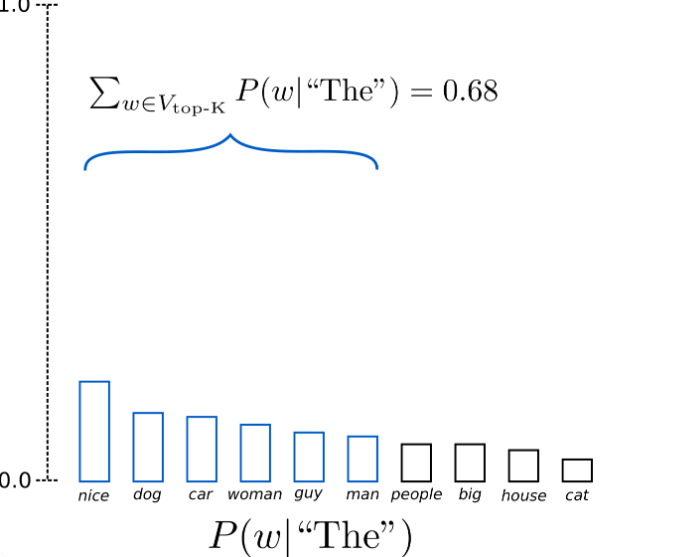
TopK是一种简单而强大的采样方案,即在采样词时,仅在概率最大的前K个词中采样,而TopP采样则是仅在累积概率超过概率p的最小单词集中进行采样
下图展示了对TopK采样中K=6时的采样操作
下图展示了对TopP采样中p=0.94时的操作
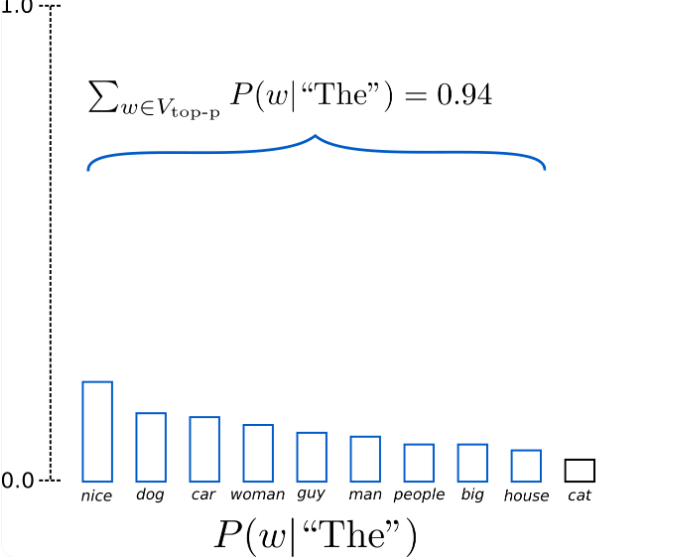
在采样时,这些操作均是对logits来进行操作,最后再softmax归一。即是对TopP,虽然其会用到softmax后的概率信息,但也是使用这些概率来去选择原本的logits(具体可见transformers的原始代码)。 对于这些操作来说,一般处理先后顺序为除以温度系数$\tau$、取TopK、取TopP、其他操作、…、取softmax归一
huggingface中使用采样:开启do_sample=True
值得注意的是如果不想开启TopK,除了有不再generate函数里面写它,还可以通过让其值为0来不开启
|
|